It’s impossible to measure the financial value of all HR focused projects.
While there may be exceptions like reducing annual leave liability or reducing insurance premiums, overall HR projects fail to have a real dollar benefit associated to them. Often this means that the HR projects are approved because decision makers intuitively feel that there will be benefits but they do not believe in actual business case.
Instead of using intuition to approve HR projects you can you Value Driver Modelling (VDM) to assess the real financial benefit of a project. Using a VDM-based tool, like the Value-Driver Psychological Assessment Tool (VD-PAT), you can specifically assess which parts of the project are going to affect which areas of the organisation and so in turn make an assessment as to the financial improvement possible from the project. Not only does this allow you to assess the value of the project by its self, but you can also assess the value across a whole portfolio of interrelated projects
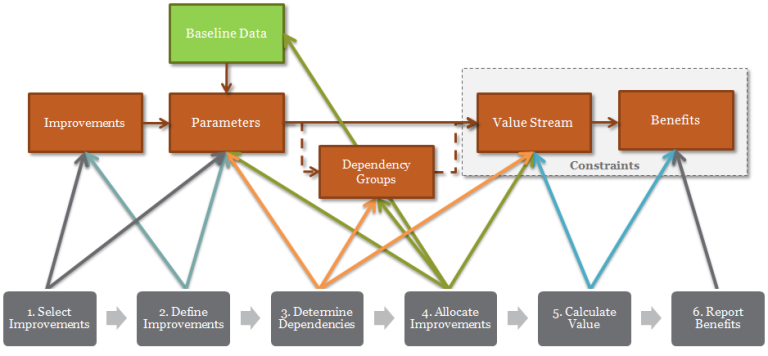
The diagram below provides an overview of how information flows into and through the VD-PAT:
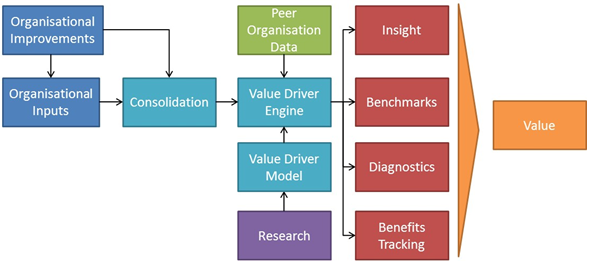
Organisational inputs provide the information required to understand how an organisation currently operates.
Inputs are collected from surveys, interviews, observations and enterprise data. The inputs may be for a single point in time or could be collected regularly over a period of time to track changes. Inputs may be collected for a specific team or unit within the organisation. Inputs may also be collected for certain aspect of an organisation, for example, job characteristics only.
Organisational Improvements are the improvements made to specific psychological factors within the organisation as part of a HR project.
An improvement may impact one or more psychological factors. It’s then possible to follow the impact that these changes have on organisation through empirically proven correlations and relationships.
There are two external inputs that provide information to the tool.
- Peer organisational data is used to compare organisational performance as well as provide information for further research.
- Research from peer-reviewed, empirical studies is used to find the inter-relationships between different organisational psychological factors. This informs the development of the Value Driver Model, which in turn drives the formation of the Value Driver Engine.
Within the tool there are three main modules of processes that take inputs and transform them into valuable outputs
- Consolidation is the module that takes raw data and transforms it into information that can be feed into the Value Driver Engine. This ensures that the outputs are meaningful and accurate.
- The Value Driver Model is the framework of causal relationships and correlations that determine how organisations actually function.
- The Value Driver Engine is the powerhouse of the tool that combines the input information with the Value Driver Model to produce valuable outputs.
There are 5 valuable outputs from the VD-PAT.
1. Insight
Insight is the culmination of the value available through all the outputs of the tool. Specifically, insight takes the current state of the organisation and identifies a portfolio of improvements and strategies that match the organisation’s need. Additionally, it also produces a thorough business case based on the costs of implementation and the resulting benefits expected from the change.
2. Benchmarks
The engine can benchmark the relative performance of the organisation against peers in the same sector or geography, or compare them against the entire population of data available to the tool.
3. Diagnostics
Results can be used to define the nature of the organisation allowing decision-makers to understand the main factors currently contributing or detracting from the organisation’s performance. Results can also be used to compare different organisational units to understand what contextual or psychological factors are impacting their relative performance. Lastly, results can be used to reinforce or dismiss anecdotal theories describing what is affecting the organisation’s performance.
4. Benefits Tracking
When a change has occurred in an organisation to improve its performance, the resulting change can be compared to baseline figures as well as tracked overtime. This can provide evidence as to the success of the improvement, or act as an early warning that additional intervention is required to ensure that the improvement meets its expected improvement goals.
5. Value
Ultimately, the purpose of the tool is to equip decision-makers with the information and insight they require to improve how the organisation performs.
Try it yourself
I’ve built a very limited prototype of the VD-PAT based on Job Characteristic Model (JCM) theory. You can download a copy of the prototype here in Excel.
The first spreadsheet (1. Research) provides you with an overview of the Job Characteristics Model (JCM), which sets the structure for the second spreadsheet (2. Model). The model transforms the JCM into a VDM. The third spreadsheet (3. Survey) provides some external input data for our model while the fourth spreadsheet (4. Consolidation) takes the results and make them readable to the 5. Engine. This engine calculates the results from the survey so we can see how satisfaction, growth satisfaction, and motivation are affected. The spreadsheet ‘7. Benchmark’ combines the peer organisation data from ‘6. Peer Organisation Data’ to allow you to benchmark your own performance.
To follow the process from start to finish, start with Research spreadsheet. Note that the collective relationships are carried across to the Model spreadsheet. Next the Survey collects key information from the participant (this can be aggregated to be more than one person). Next the survey data is combined into a structure that can be read by the VD-PAT on spreadsheet Consolidation (this is generally a more important step for when you’re not using excel). Then Engine combines the survey results with the framework of the JBC theory to tell us what benefits we’d expect to receive. This information can then either be benchmarked against other organisations or can be used to value, in terms of dollars, the likely benefit (Intervention).